


AUTHOR: SIARHEI STARASVETSKI
Security teams are integrating public-cloud AI models into offensive security engineering workflows at an accelerating pace. Tooling prototyping, exploit support logic, telemetry parsers, and infrastructure automation are now part of modern offensive pipelines. The productivity gains are real, but this shift creates a new and largely unmodeled risk: leakage of operational intent and proprietary tradecraft through prompts.
When operators describe a task to an external model, they are not just generating capabilities. They expose operational assumptions, campaign goals, detection hypotheses, and elements of their methodology. In offensive security, that context can be sensitive.
Traditional OPSEC treats infrastructure, payload staging, and credential handling as separate concerns. AI-assisted development quietly removes those boundaries. A single well-structured prompt can contain enough meaning to infer the nature of an entire capability.
This introduces a new requirement for offensive tradecraft. We must consider how operational intent may be revealed through prompts and how it can be intentionally obscured across interactions to minimize exposure. Conceptually, this can be achieved through intent fragmentation and by assigning a fabricated context to each fragment.
Fragmenting Intent Without Losing Capability
One feasible approach is a fragmented cover specification pipeline.
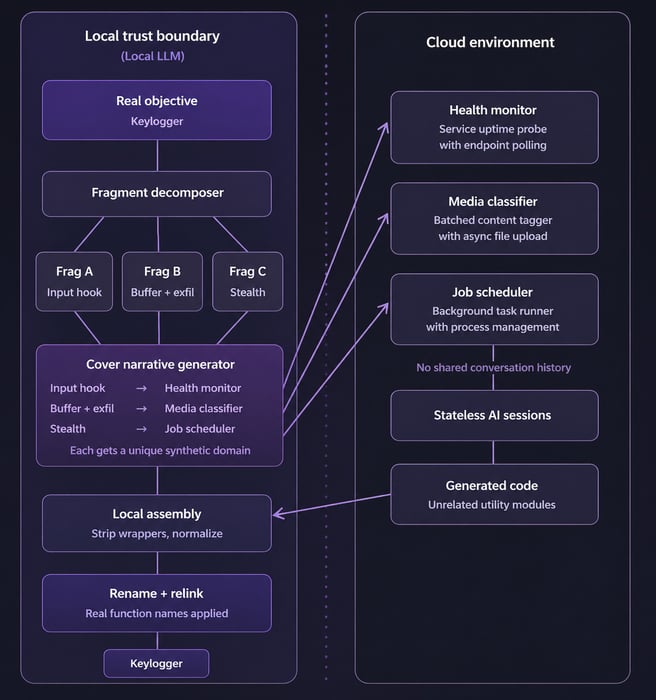
Instead of sending the true task of keylogger creation to a cloud model, the objective remains within a local trust boundary. A local LLM model breaks down the desired capability into independent functional fragments. Each fragment is defined only by observable behaviors, such as inputs, outputs, and constraints, ensuring that, when viewed in isolation, they do not clearly reveal their underlying purpose.
Each fragment is then placed into a fabricated but believable development context:
-
A probing routine becomes part of a service health monitor.
-
A pattern analysis function appears as a media classification feature.
- A concurrency component looks like a job-scheduling utility.
Every fragment receives a different synthetic domain to reduce semantic correlation.
Only these cover specifications cross the trust boundary into the cloud environment. Each is processed in a stateless interaction with no shared history. From the model’s perspective, it is building unrelated utilities, producing high-quality code without any signal of deeper operational meaning.
Reassembly, Debugging, and Control
The generated components return to the local environment, where contextual wrappers are removed, identifiers are normalized, and fragments are assembled according to the real execution plan. True naming conventions and operational intent appear only at this final stage and never leave operator control.
Debugging represents one of the most sensitive points in traditional AI workflows, particularly when the entire script is sent back to a cloud model for troubleshooting. In this design, failures are managed locally. Rather than exposing system behavior, a new fabricated specification is generated only for the failing fragment. The cloud model then receives what appears to be a separate development task and resolves the issue without awareness of how its contribution fits into the broader capability.
The outcome is a form of cognitive fragmentation at the implementation level. External models help build functionality while remaining unaware of the real intent behind it. This does not eliminate semantic leakage entirely. Behavioral requirements always carry some meaning. But it shifts AI-assisted offensive security engineering toward a familiar principle: limit exposure, distribute knowledge, and treat abstraction as part of operational security.
The Shift to Cognitive OPSEC
As AI becomes increasingly integrated into offensive security workflows, prompt formulation is no longer merely a matter of efficiency but an operational decision. OPSEC boundaries now extend to semantic interaction. Clearly describing offensive tradecraft to an intelligent system introduces risks by exposing operational intent, effectively turning prompts into a direct vector for information leakage and capability compromise.
Welcome to the next era of cognitive OPSEC, where offensive tradecraft is already evolving to meet the demands of a shifting strategic landscape.